
Abstract
We focus on the task of identifying the location of target regions from a natural language instruction and a front camera image captured by a mobility. In autonomous driving scenarios, such an instruction could become invalid due to the movement of the mobility itself, expecting the prediction of a `no-target' response when no region in the image corresponds to the instruction. This task is challenging as it requires both existence prediction and segmentation mask generation, especially for stuff-type target regions with ambiguous boundaries.
Existing methods often underperform in handling stuff-type target regions, as well as absent or multiple targets. To overcome these limitations, we propose GENNAV that predicts target existence and generates segmentation masks for multiple stuff-type target regions. To evaluate GENNAV, we constructed a novel benchmark, GRiN-Drive, which includes three distinct types of samples: no-target, single-target, and multi-target.
GENNAV achieved superior performance over baseline methods on standard evaluation metrics. Furthermore, we conducted real-world experiments with four automobiles operated in five geographically distinct urban areas to validate its zero-shot transfer performance. In these experiments, GENNAV outperformed baseline methods and demonstrated its robustness across diverse real-world environments.
Real-World Experiments

Fig. 1: Qualitative results of the proposed method in the real-world zero-shot transfer experiments. The green and red regions indicate the predicted and ground-truth regions, respectively, while the yellow region represents the overlap between the predicted and ground-truth regions.
Overview
We tackle the task of predicting both the existence and location of target regions based on a natural language instruction and a front camera image taken from a moving mobility. We define this task as Generalized Referring Navigable Regions (GRNR).

Fig. 2: Typical examples of the GRNR. Left: single target. Center: multi-target. Right: no-target. The goal is to generate zero or more segmentation masks (shown in green). Unlike the RNR, the GRNR accommodates instructions specifying an arbitrary number of landmarks, including cases where multiple target regions exist or no target region exists. The bounding boxes indicate the landmarks referenced in the instructions.
-
CORE NOVELTIES:
- 1. Existence Aware Polygon Segmentation Module (ExPo) predicts the existence of target regions and generates polygon-based segmentation masks by integrating four types of information: linguistic features, estimated road surface features, fine-grained visual representations and spatially grounded multimodal representations.
- 2. Landmark Distribution Patch Module (LDPM) models fine-grained visual representations related to potential landmarks by patchifying images based on the spatial distribution of landmarks.
- 3. Visual-Linguistic Spatial Integration Module (VLSiM) models the relationship between language and spatial information by integrating features derived from an image overlaid with a pseudo-depth image and a segmentation mask of the road region, and aligning the resulting representation with linguistic features.
- 4. GRiN-Drive Benchmark is a comprehensive evaluation benchmark including three distinct types of samples: single-target, no-target, and multi-target.
- 5. Extensive Real World Zero-Shot Transfer Experiments validates the performance of GENNAV through real-world experiments involving four automobiles operating across five geographically distinct urban areas.
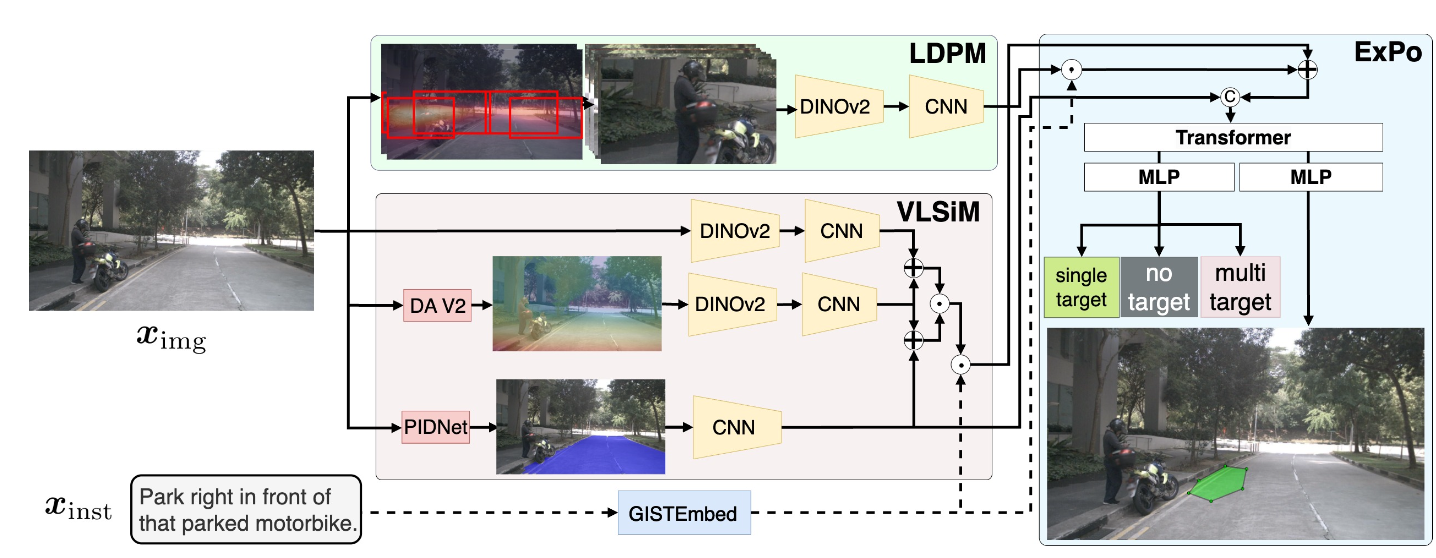
Fig. 3: Overall architecture of GENNAV. The green, red, and blue regions in this figure represent the LDPM, VLSiM, and ExPo modules, respectively. Given a natural language instruction and a front camera image taken from a moving mobility, our model outputs prediction of both the existence and location of target regions.
Results
Qualitative Results

Fig. 4: Qualitative results of the proposed method and baseline methods on the GRiN-Drive benchmark. Panels (a), (b), (c) and (d) show the prediction by LAVT, TNRSM, bbox-based segmentation method Qwen2-VL and GENNAV, respectively. The green and red regions indicate the predicted and ground-truth regions, respectively, while the yellow region represents the overlap between the predicted and ground-truth regions.

Fig. 5: Additional qualitative results of the proposed method in the GRiN-Drive benchmark. The green and red regions indicate the predicted and ground-truth regions, respectively, while the yellow region represents the overlap between the predicted and ground-truth regions.

Fig. 6: Additional qualitative results of the proposed method in the real-world experiments. The green and red regions indicate the predicted and ground-truth regions, respectively, while the yellow region represents the overlap between the predicted and ground-truth regions.
Quantitative Results
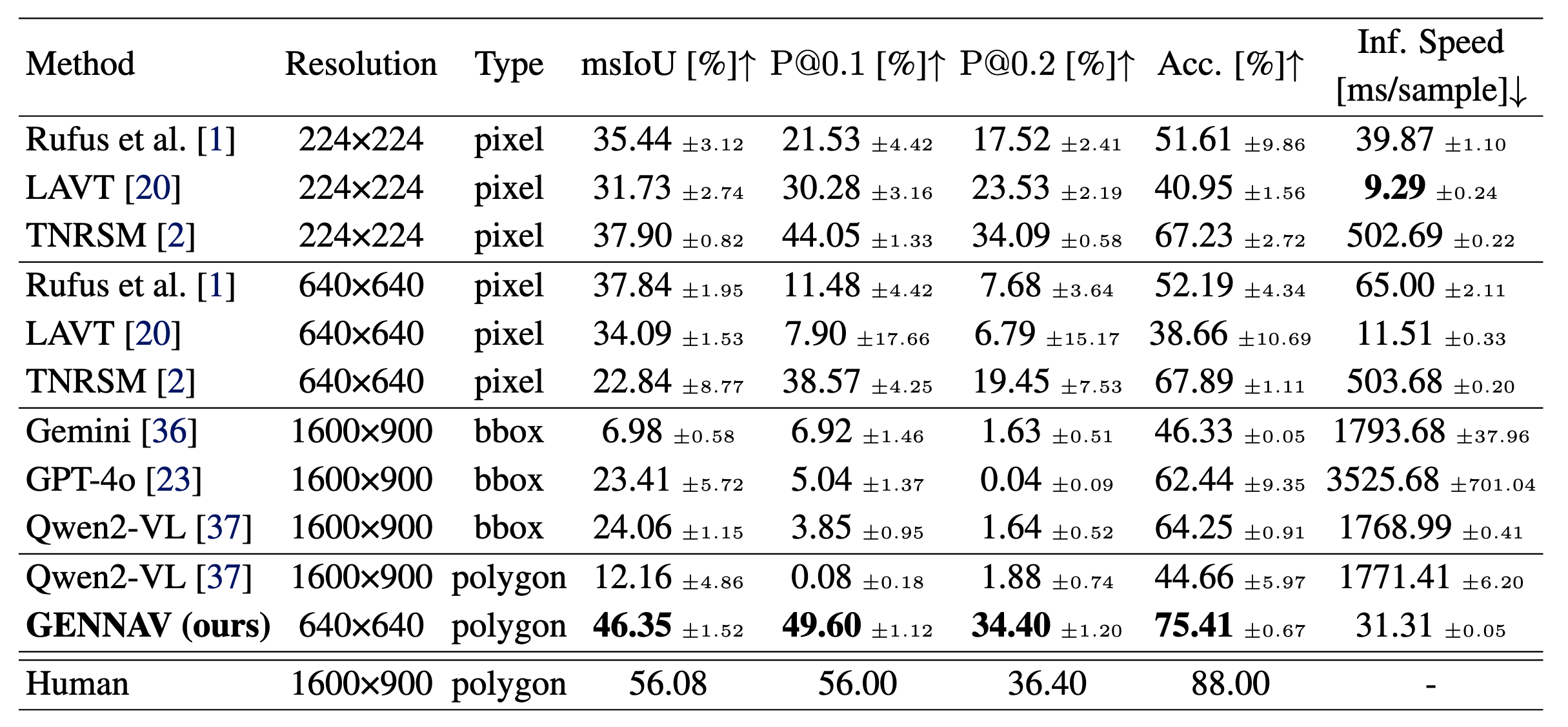
Table 1: Quantitative results. The best results are marked in bold.
BibTeX
@inproceedings{
katsumata2025gennav,
title={{GENNAV: Polygon Mask Generation for Generalized Referring Navigable Regions}},
author={Kei Katsumata and Yui Iioka and Naoki Hosomi and Teruhisa Misu and Kentaro Yamada and Komei Sugiura},
booktitle={9th Annual Conference on Robot Learning},
year={2025}
}